
Predicting Artists
As of late I have become very interested in both machine learning and computer vision. While thinking of a project to work on both of these skills I thought it would be interesting to build a program that would be able to predict an artist based on a painting. I have become pretty comfortable using Sci-Kit Learn for machine learning, but wasnt sure the best route to go for the vision portion of this project. After some research I found OpenCV would be best for this type of work. Developed by Intel, OpenCV is a free, open source computer vision library written in C++. It has a huge online community and bindings for several languages, including Python, my language of choice.

“We are surrounded by curtains. We only perceive the world behind a curtain of semblance. At the same time, an object needs to be covered in order to be recognized at all.”
― René Magritte
After I had my idea finalized and the appropriate tools ready the next step was getting some data. After writing a script to scrape images from the google image API I was able to get one hundred twenty images. Sixty paintings by René Magritte and sixty paintings by Salivador Dalí. One caveat of this approach is the fact that not all of these images are actual paintings by the artist but rendtions of them by others and photoshop jobs however they still maintain the overall style of the original artist so I chose to keep moving. One hundred twenty images is also a very small number for this type of problem but its enough for the scope of this project.
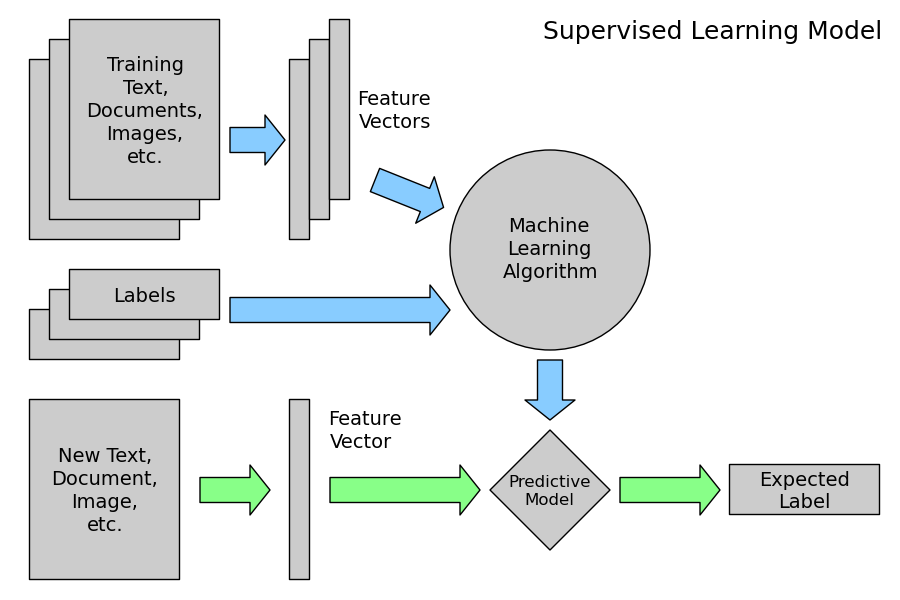
After I had all of my data I needed to start thinking about what features I was going to extract to construct the model. This problem is an example of classification, a branch of supervised Machine Learning. Basically we take a bunch of data, in this case it is paintings, label them with the correct classes, Magritte or Dali, and then create a feature vector. This feature vector is completely dependent on domain you are working in, more on this in a minute. You then input this feature vector into a machine learning algorithm which creates a predictive model. At this point can show the model new unlabeled data and it will give you a prediction of the class. Here is a very helpful diagram of this process.
At this point the problem became what I was going to use for the feature vectors of all of my images. After some more research I decided to use the RGB values of each image for my features. Every pixel in an image is assigned three digits in the format (Red, Green, Blue) the values are of each are equal to the intensity of the color and range from 0 to 255. Below is a simple example of this.
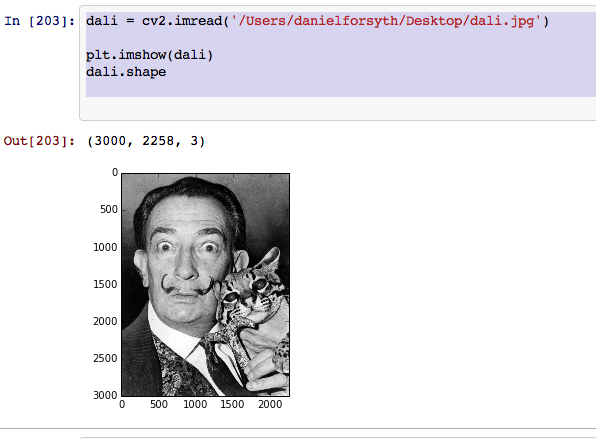
This snippet is reading in an image from the desktop, using matplotlib to display it, and then displaying the shape of the image. Since the image is 3000x2258 the shape of the numpy array is 3000X2258X3. This introduces another problem, the fact that all the images are different sizes. I also noticed that when OpenCV reads an image it converts it into a numpy array in the format (Blue, Green, Red). To overcome these two problems I wrote a small function.
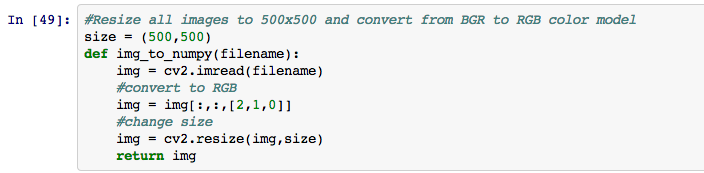
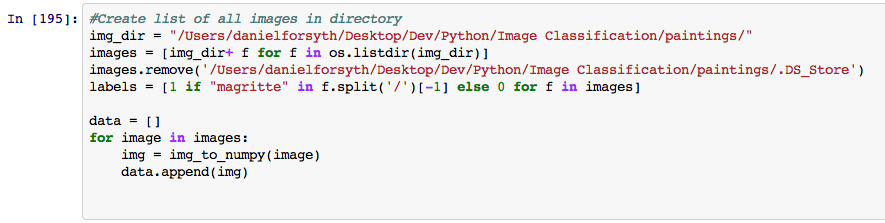
At this point we are ready to get all of the data ready for Sci-Kit Learn. In the code below I created a list of numpy arrays for all of the images, I also created a list called labels which designates which artist the painting belongs to.
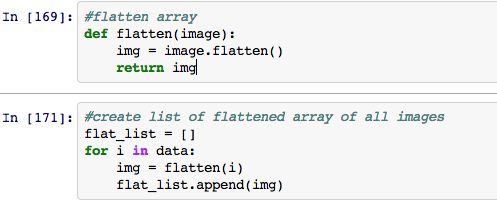
Sci-Kit Learn takes a two dimensional array [n samples x n features] so we have to flatten our arrays before we input them. The below code creates a list of flattened arrays for each image.
We now have all our data in the correct format for inputting into Sci-Kit. But before we do this we must split our data to avoid overfitting. Sci-Kit learn has a handy method for this, called train test split. The below code splits the flattened array of images into two seperate sets. The training set which is 70% of the data and the testing set which is 30%. Each image has 750,000 features which comes from the fact that each image is 500x500x3. So we train on the 70% and then make predictions on the remaining 30%.

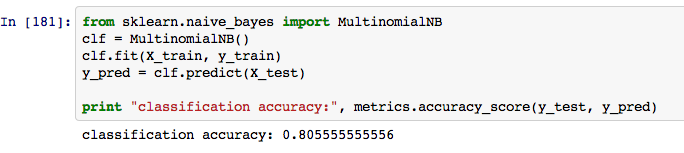
Finally we are ready to start making predictions. After trying out a few different classifiers including SGD, SVM, SVC, and a few different variations of Naive Bayes I found I got the best results with the Multinomial Naive Bayes classifier. The code for this is below where I was able to achieve 80% prediction accuracy, not bad for 120 samples.
For future work on this project I would like to:
- Scrape much more data, possibly add artists
- Look into more options for feature extraction of images
- Learn and implement grid seach for hyperameter optimaztion
- Implement the entire project into a web front end
I have added all the code for this project to my github available here as well as the full iPython notebook here
I am still very much new to all of this for any typos, code errors, advice, questions, or anything else, please get in touch via Twitter or email me at danforsyth1@gmail.com. I'd love to hear from you!