
NBA Twitter, Emojis, and Word Embeddings
A few weeks ago I read this blog post from the Instagram engineering team on machine learning and emoji trends. The post talked about general emoji usage over time on Instagram and then used word2vec an algorithm that uses a unsupervised learning process to read through a corpus of text and is then able to predict the context around a given word or emoji. The famous example of this word embedding method is vector['king'] - vector['man] + vector['woman'] = ['queen']. When I first read this post the NBA playoffs had recently started so I decided I would collect tweets pertaining to the playoffs and then try and use the same techniques Instagram used on the tweet dataset.

I used the same process I used to collect tweets about an NHL game for this project however for the search terms I used the name of every starting player on each team that remained in the playoffs on May 11th. Over the last thirty six days I was able to collect 8,520,786 tweets. This was up until the beginning of game six of the finals. Once I had all of the tweets on my local machine I was able to start analyzing them.
The first thing I wanted to do was create a pandas dataframe of all of the tweets and then drop all duplicate tweets, retweets, and tweets that contained a URL.
import pandas as pd
pd.options.display.max_colwidth = 0
df = pd.read_csv('/Users/danielforsyth/desktop/tweets.csv', encoding='utf-8')
tweets = df['text'].drop_duplicates().values.tolist()
tweets = [x for x in tweets if not x.startswith('RT')]
tweets = [i for i in tweets if not ('http://' in i or 'https://' in i)]
Now that I had a filtered list of tweets I wanted to find all of the emojis used in the tweets. First I used a regex pattern to capture all of the emojis and then created a pandas series to find the top 25 most used emojis.
import re
try:
# UCS-4
e = re.compile(u'[\U00010000-\U0010ffff]')
except re.error:
# UCS-2
e = re.compile(u'[\uD800-\uDBFF][\uDC00-\uDFFF]')
emojis = []
for x in tweets:
match = e.search(x)
if match:
emojis.append(match.group())
dfe = pd.DataFrame(emojis,columns=['text'])
pd.Series(' '.join(dfe['text']).lower().split()).value_counts()[:25]

The 'face with tears of joy' emoji came in first place being used 67,884 times. This is interesting because this emoji was also the most used in Instagram's results of more than 50 millions comments and captions.
The final thing I wanted to do was create a word2vec model using the tweets and see what type of results I could find. I used the genism library which makes setting up a model pretty trivial.
wt = [list(x.split()) for x in tweets]
import logging
logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s',\
level=logging.INFO)
# Set values for various parameters
num_features = 400 # Word vector dimensionality
min_word_count = 5 # Minimum word count
num_workers = 4 # Number of threads to run in parallel
context = 10 # Context window size
downsampling = 1e-3 # Downsample setting for frequent words
from gensim.models import word2vec
print "Training model..."
model = word2vec.Word2Vec(wt, workers=num_workers, \
size=num_features, min_count = min_word_count, \
window = context, sample = downsampling)
model.init_sims(replace=True)
After creating the model, which could take some time depending on your machine and the size of the dataset, you can start performing some various syntactic/semantic NLP word tasks.
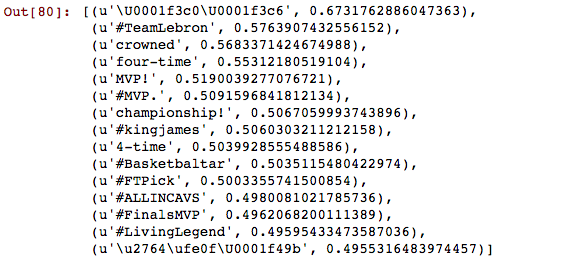
model.most_similar('🏆'.decode('utf-8'),topn=15)
model.most_similar('dunk',topn =15)
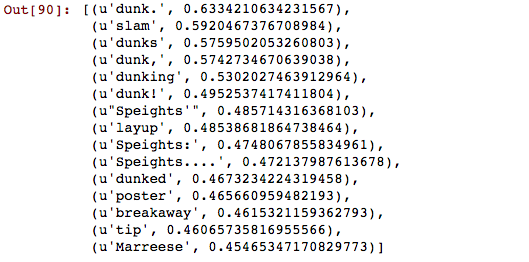
You can see there is quite a few references to this Marreese Speights missed dunk:
model.most_similar('chef',topn=15)
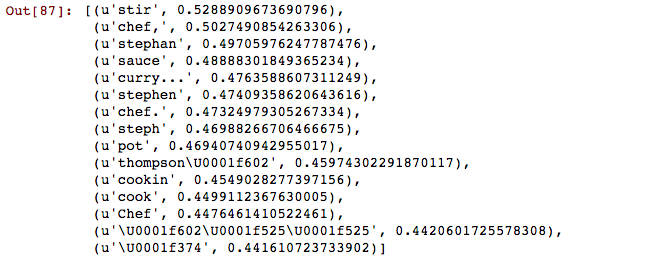
"Been cookin' with the sauce, chef, curry with the pot, boy 360 with the wrist, boy." -Drake
What I found to be the most interesting was what happened when I ran the similarity method with both MVP candidates and the word 'MVP'.
model.similarity('james', 'mvp')

model.similarity('curry', 'mvp')
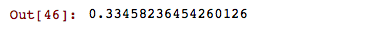
It looks like twitter believes Stephen Curry is more deserving of the finals MVP trophy.
It was very interesting using word2vec for the first time as it was quite easy to setup and get results compared to other NLP techniques. In the future I would like to spend some more time working with word2vec particularly with a different and larger dataset.
If you have any questions, feedback, advice, or corrections please get in touch with me on Twitter or email me at danforsyth1@gmail.com.